
Stable diffusion DeepGPU(AIACC)加速社区版
Stable Diffusion AIACC加速版部署
免责声明:本服务由第三方提供,我们尽力确保其安全性、准确性和可靠性,但无法保证其完全免于故障、中断、错误或攻击。因此,本公司在此声明:对于本服务的内容、准确性、完整性、可靠性、适用性以及及时性不作任何陈述、保证或承诺,不对您使用本服务所产生的任何直接或间接的损失或损害承担任何责任;对于您通过本服务访问的第三方网站、应用程序、产品和服务,不对其内容、准确性、完整性、可靠性、适用性以及及时性承担任何责任,您应自行承担使用后果产生的风险和责任;对于因您使用本服务而产生的任何损失、损害,包括但不限于直接损失、间接损失、利润损失、商誉损失、数据损失或其他经济损失,不承担任何责任,即使本公司事先已被告知可能存在此类损失或损害的可能性;我们保留不时修改本声明的权利,因此请您在使用本服务前定期检查本声明。如果您对本声明或本服务存在任何问题或疑问,请联系我们。
概述
stable diffusion可以通过使用文字生成图片,在整个pipeline中,包含CLIP或其他模型从文字中提取隐变量;通过使用UNET或其他生成器模型进行图片生成。通过逐步扩散(Diffusion),逐步处理图像,使得图像的生成质量更高。通过本文,客户可以搭建一个stable diffusion的webui框架,并使用aiacctorch加速图片生成速度。在512x512分辨率下,AIACC加速能将推理性能从1.91s降低至0.88s,性能提升至2.17倍,同时AIACC支持任意多LORA权重加载,且不影响性能。 aiacctorch支持优化基于Torch框架搭建的模型,通过对模型的计算图进行切割,执行层间融合,以及高性能OP实现,大幅度提升PyTorch的推理性能。您无需指定精度和输入尺寸,即可通过JIT编译的方式对PyTorch框架下的深度学习模型进行推理优化。具体详见手动安装AIACC-Inference(AIACC推理加速)Torch版。

计算巢实例创建
创建实例
点击创建 Stable diffusion AIACC加速社区版 实例,选择所需版本,单机版或多机集群版: 
选择所需地域:  勾选实例类型,并填写实例密码:
勾选实例类型,并填写实例密码: 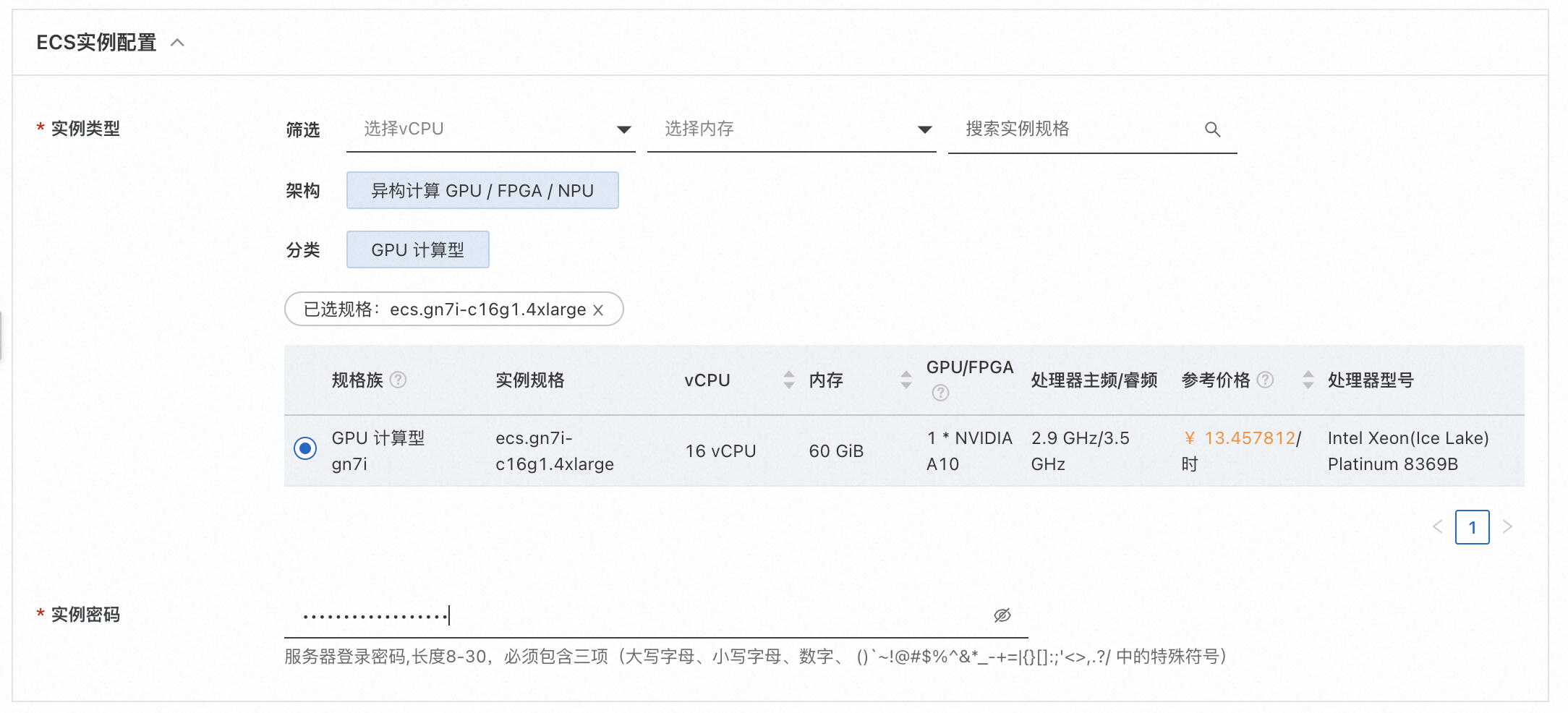 填写登录用户名和密码,用户名和密码在后续登录webui时使用:
填写登录用户名和密码,用户名和密码在后续登录webui时使用:  点击下一步:确认订单,并勾选服务条款,点击创建:
点击下一步:确认订单,并勾选服务条款,点击创建: 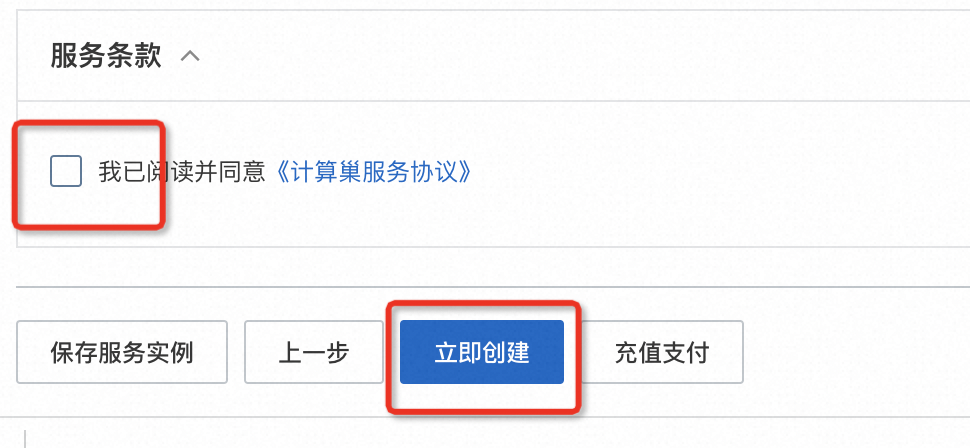 稍等片刻,等待部署完成。
稍等片刻,等待部署完成。
执行图片生成测试
登录页面
点击计算巢控制台中的实例: 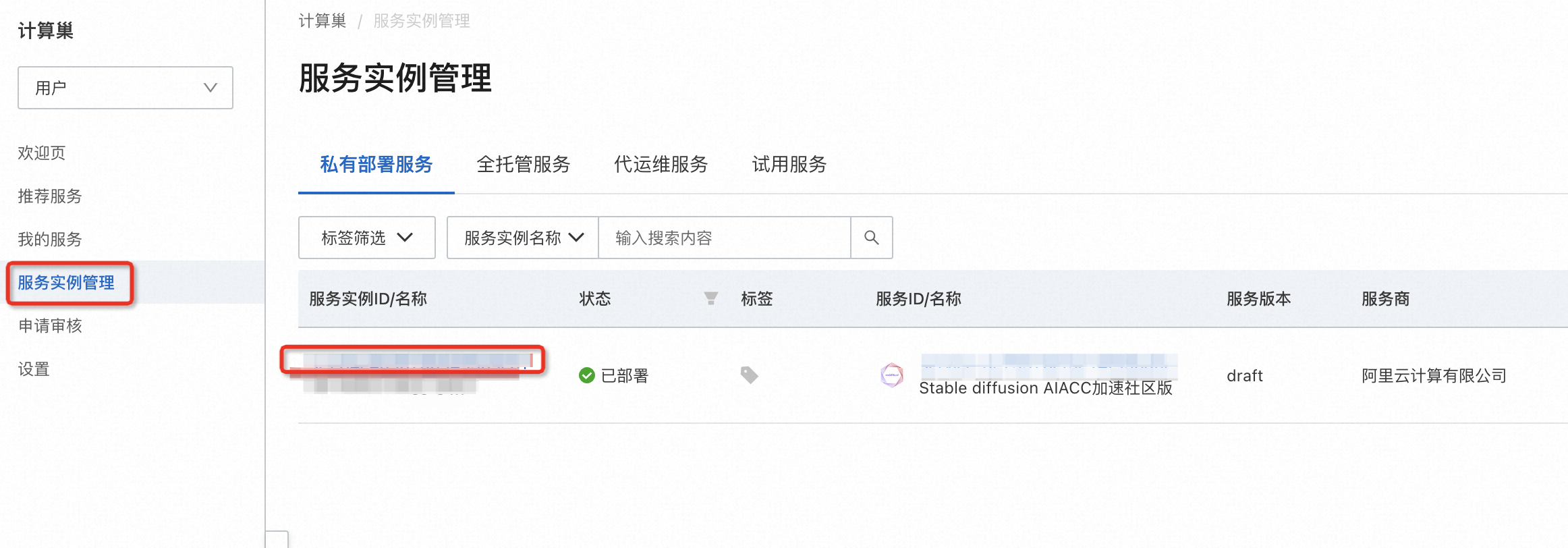 点击其中的endpoint网址:
点击其中的endpoint网址: 
测试
输入登录信息中的用户名和密码登录:  进入测试页面:
进入测试页面: 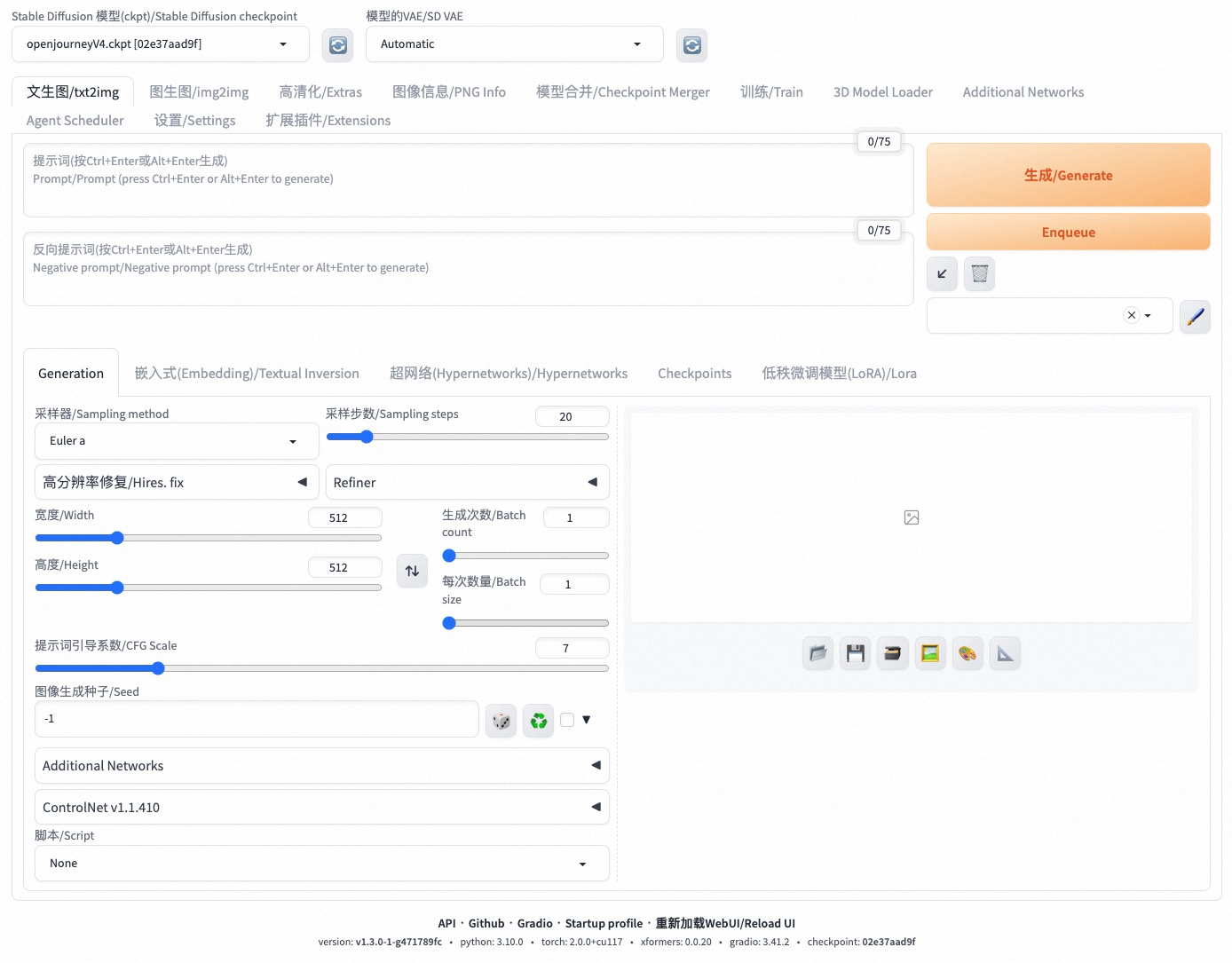 注意,由于taiyi中文模型很久没有更新,不适配webui1.6以上版本,因此将其移除。 输入prompt,例如:
注意,由于taiyi中文模型很久没有更新,不适配webui1.6以上版本,因此将其移除。 输入prompt,例如:
city made out of glass : : close shot : : 3 5 mm, realism, octane render, 8 k, exploration, cinematic, trending on artstation, realistic, 3 5 mm camera, unreal engine, hyper detailed, photo – realistic maximum detail, volumetric light, moody cinematic epic concept art, realistic matte painting, hyper photorealistic, concept art, volumetric light, cinematic epic, octane render, 8 k, corona render, movie concept art, octane render, 8 k, corona render, cinematic, trending on artstation, movie concept art, cinematic composition, ultra – detailed, realistic, hyper – realistic, volumetric lighting, 8 k
点击生成,即可生成如下图片: 
此处我们使用了aiacctorch加速了模型,可以看到单张图片推理时间为0.88s。(注意,首次应用aiacctorch进行图片生成,或者切换模型后的首次图片生成,会多占用10s时间,以进行aiacctorch模型加载)。
模型切换
在测试镜像中,我们预装了7个模型 :
- 512-base-ema.safetensors:512x512 Stable Diffusion 2.0模型
- 768-v-ema.safetensors:768x768 Stable Diffusion 2.0模型
- openjourneyV4.ckpt:openjourney 模型
- sd_xl_base_1.0_0.9vae.safetensors:SDXL base模型
- sd_xl_refiner_1.0_0.9vae.safetensors:SDXL refiner模型
- v1-5-pruned-emaonly.safetensors:Stable Diffusion 1.5模型
- v2-1_768-ema-pruned-fp16.safetensors:Stable Diffusion 2.1模型
我们可以根据输入文字以及生成图片风格,切换模型进行模型推理,例如我们可以通过左上侧的选项卡,选择 512-base-ema.safetensors模型: 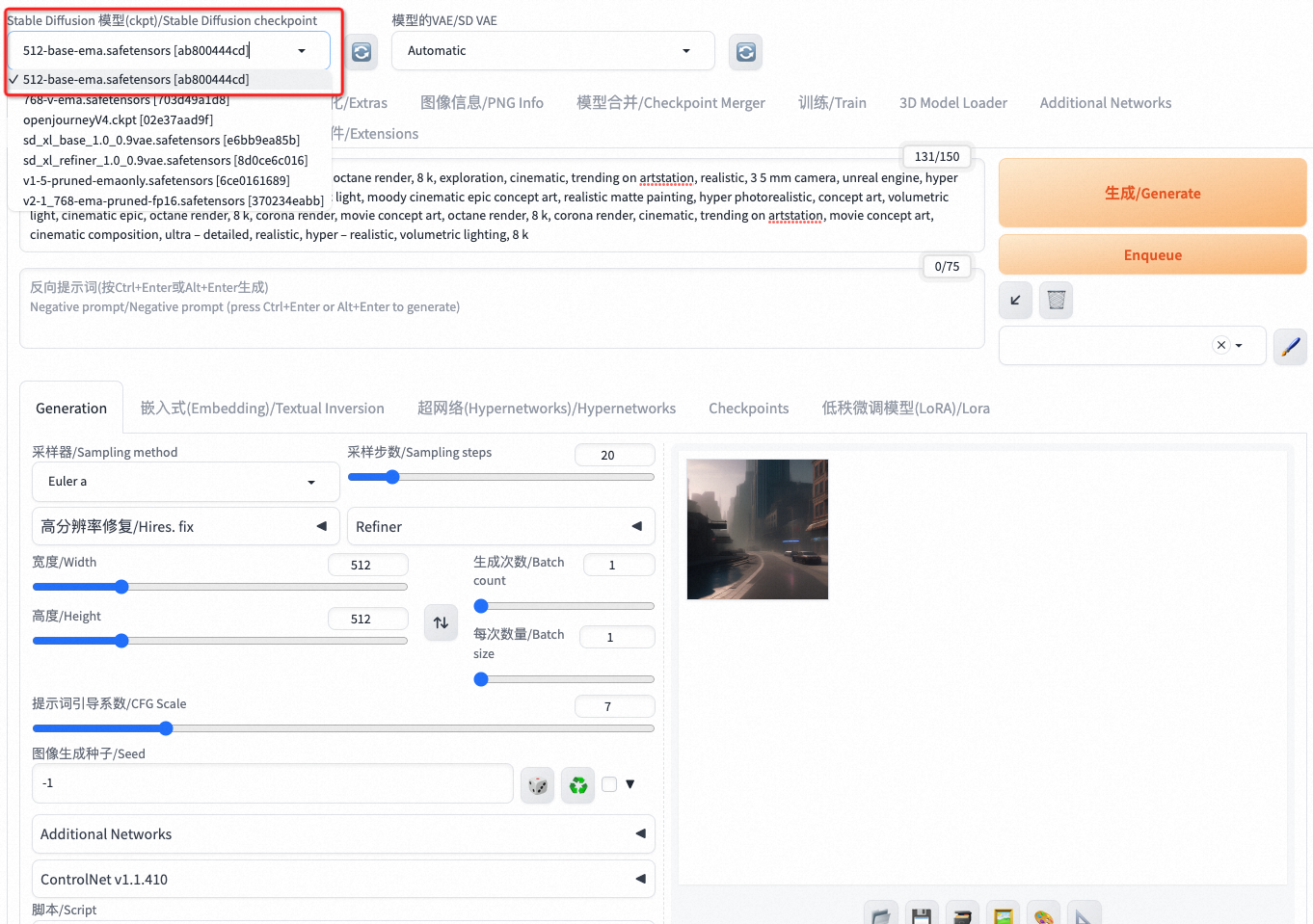 而后输入提示词:
而后输入提示词:
city made out of glass : : close shot : : 3 5 mm, realism, octane render, 8 k, exploration, cinematic, trending on artstation, realistic, 3 5 mm camera, unreal engine, hyper detailed, photo – realistic maximum detail, volumetric light, moody cinematic epic concept art, realistic matte painting, hyper photorealistic, concept art, volumetric light, cinematic epic, octane render, 8 k, corona render, movie concept art, octane render, 8 k, corona render, cinematic, trending on artstation, movie concept art, cinematic composition, ultra – detailed, realistic, hyper – realistic, volumetric lighting, 8 k
则可生成如下图所示的图像: 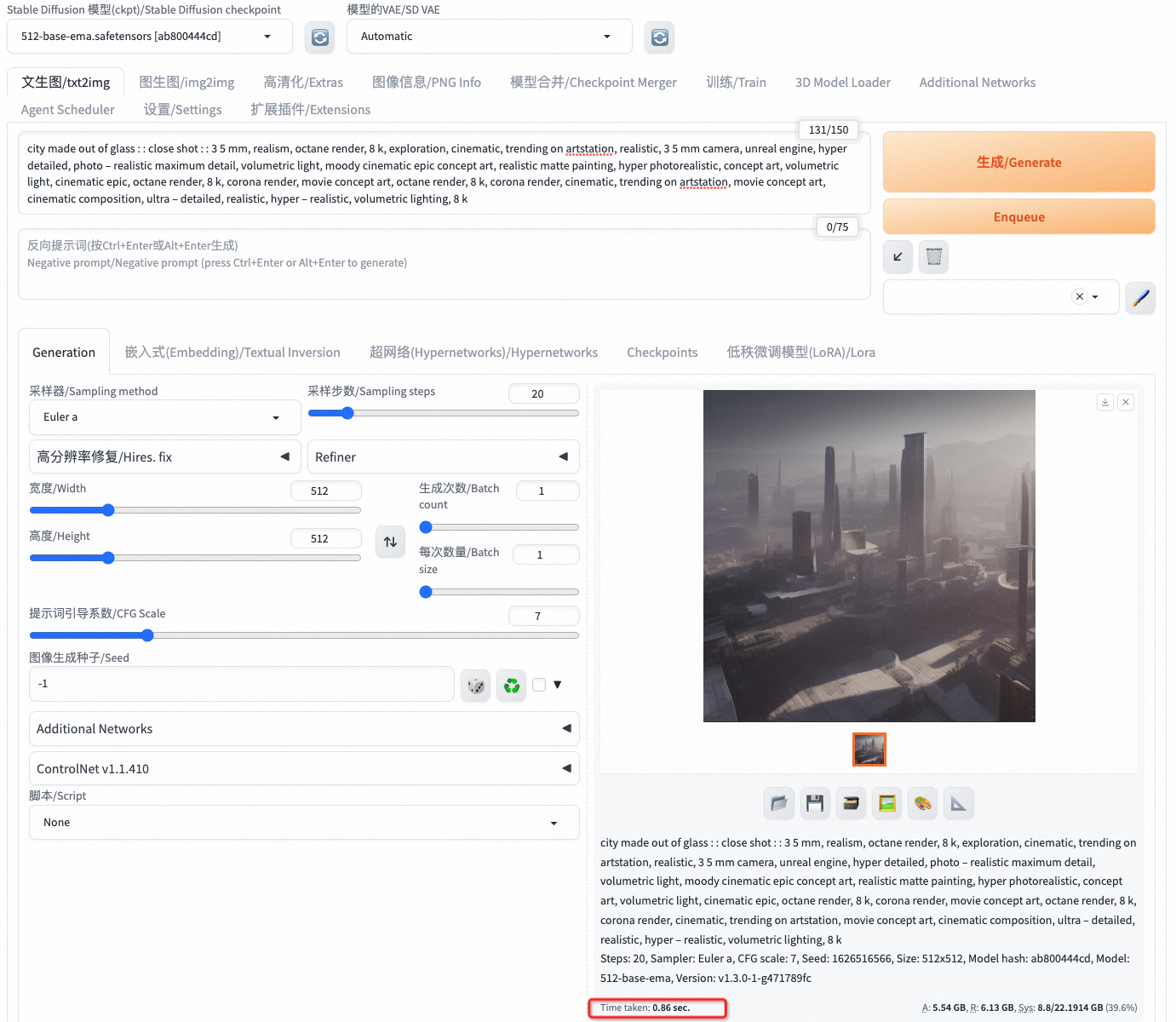
LORA功能试用
aiacctorch支持LORA加速,可以在prompt中加入LORA支持文本:

可见在aiacctorch加速优化下,LORA加载后性能与加载前相同。
Controlnet功能试用
Controlnet可以帮助我们生成与原始图相似风格或相似布局的图片,这里以canny为例介绍controlnet功能。 打开Controlnet选项卡,选择controlType为Canny,并上传一张图片,以LENA图为例,进行如下设置:

点击生成: 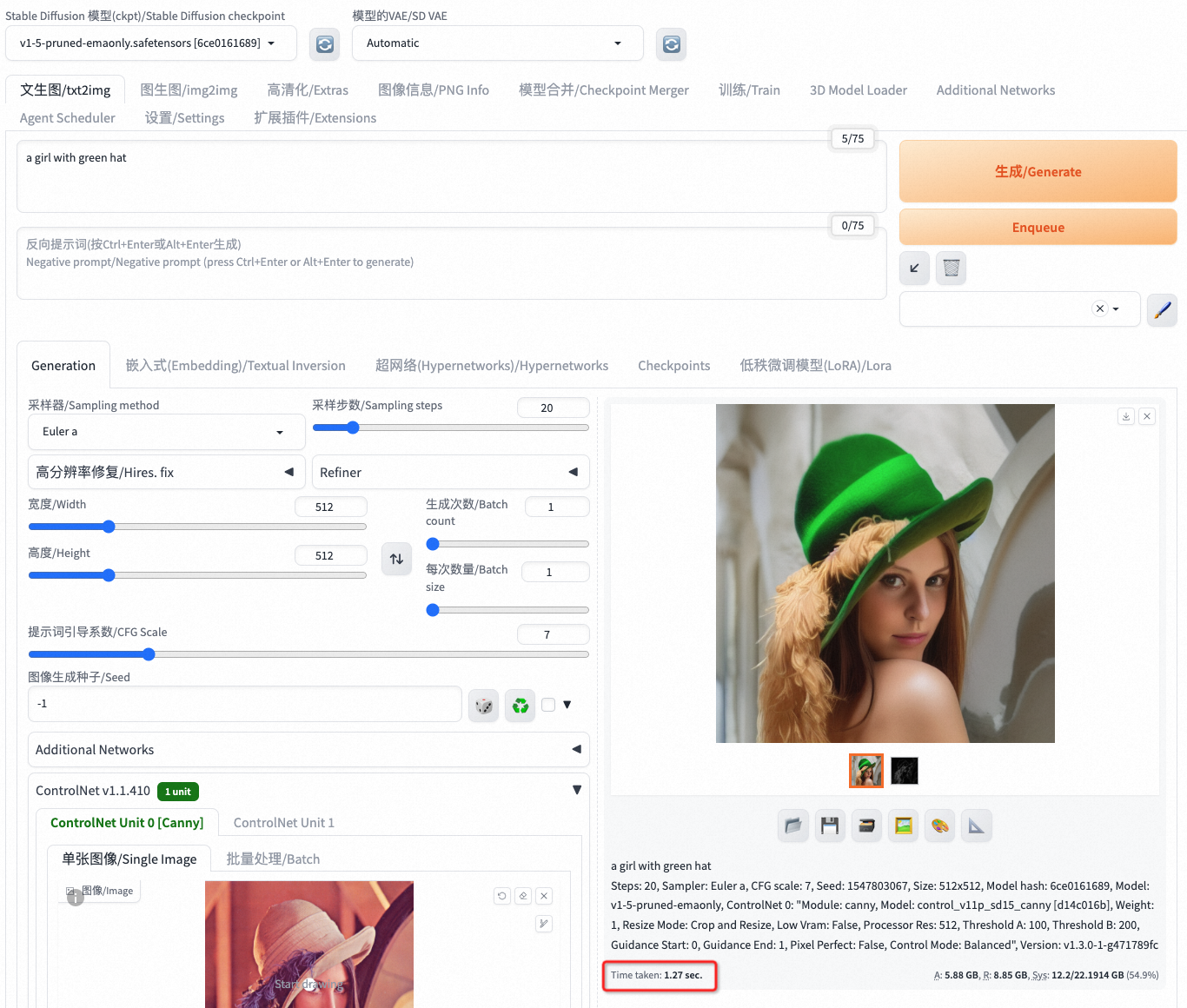 可见性能为1.27s。
可见性能为1.27s。
禁用AIACC加速
我们也可以在settings中禁用aiacctorch。点击settings选项卡,选中aiacctorch,去掉"Apply Aiacctorch in Unet to speedup the whole network inference when loading models"前方的勾,而后点击应用设置: 
而后在控制台的运维管理中点击重启服务:  稍等片刻即可
稍等片刻即可
推理性能数据汇总
以下是在A10上使用webUI测得的AIACC同pytorch的性能比例,注:以下数据为关闭了生成图输出到文件的过程 
F&Q
如何重启服务
- 可使用如下命令停止服务:
systemctl stop sdwebui
- 可使用如下命令打开服务:
systemctl start sdwebui
如何查看log
cat /var/log/sdwebui.log
出现AttributeError: 'NoneType' object has no attribute 'loaded_loras'怎么解决
如果使用dreambooth库,则会导致内置的lora模块失效,则会出现如下问题:

需要解决这个问题,请关闭sd_dreambooth_extension:  而后应用并重启界面, 然后重启服务:
而后应用并重启界面, 然后重启服务:
systemctl stop sdwebui
systemctl start sdwebui
如何设置服务进程退出后自动重启
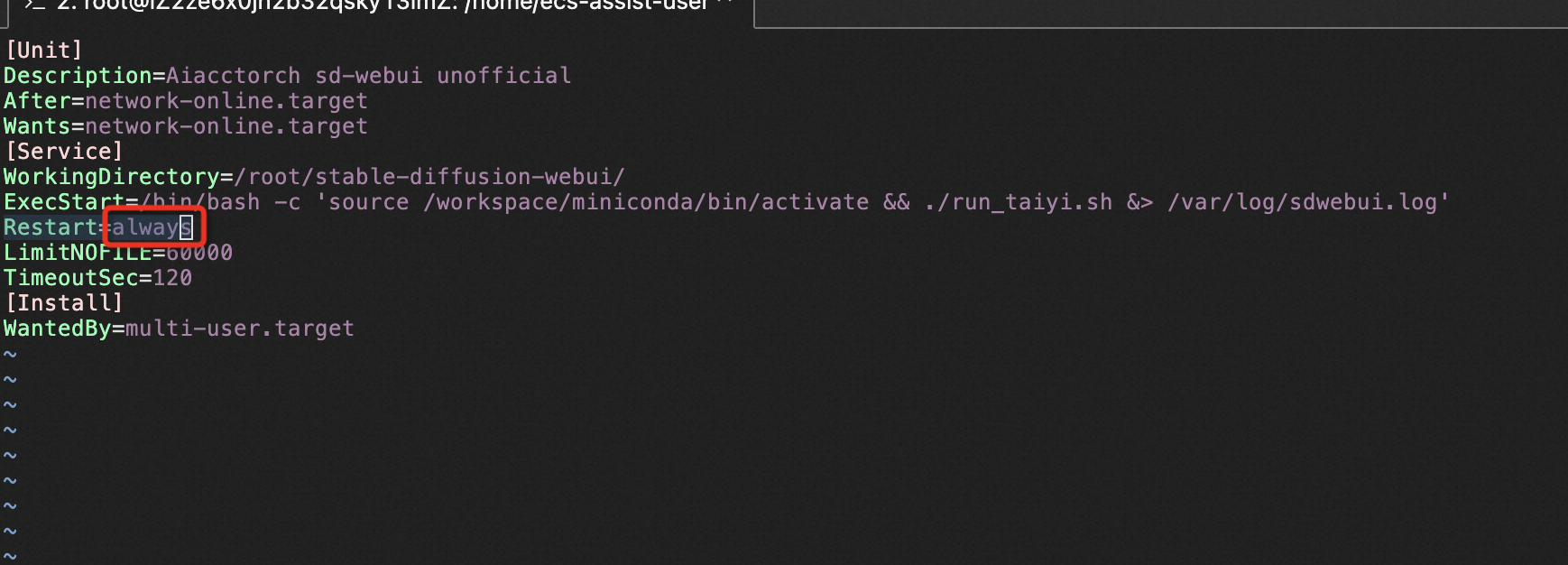
- 修改/lib/systemd/system/sdwebui.service,将Restart设置成always,则服务进程异常退出后会立刻重启。
如何预编译模型
- aiacctorch通过编译优化的方式进行模型加速。当切换模型时,aiacctorch也会同步编译模型。如果我们希望将已有的模型全部进行编译,则可以通过webui的切换模型的api进行。
- 请注意,切换模型时请确保webui已经打开,由于webui是单进程模式,单个机器请执行单个切换模型的操作。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Wed May 24 11:13:15 2023
@author: lyuniqi
"""
import requests
import random
import base64
ip_address = "http://localhost:5001"
url_option = ip_address + "/sdapi/v1/options"
url_sd_models = ip_address + "/sdapi/v1/sd-models"
url_txt2img = ip_address + "/sdapi/v1/txt2img"
models = [x['title'] for x in requests.get(url_sd_models).json()]
def change_option(model_name):
print(f"change to {model_name}")
option = {"sd_model_checkpoint":model_name}
requests.post(url_option, json=option)
for model in models:
change_option(model)
如何保存预编译模型
预编译模型放置在~/.cache/aiacctorch/eng_models/当中,如果需要将预编译模型放置在其他位置,则可使用软链接的方式进行。例如将预编译模型放置在/root/prebuild_models:
#新建文件夹
mkdir -p /root/prebuild_models
#移动目录
mv ~/.cache/aiacctorch/* /root/prebuild_models
#创建软链接
rm ~/.cache/aiacctorch/ && ln -s /root/prebuild_models ~/.cache/aiacctorch/